爱游戏 入口
跳过主要内容
2021年10月31日,
互联网
电脑
手机
ios爱游戏
平面设计和视频编辑
家庭影院及音响
工业技术
互联网
电脑
手机
ios爱游戏
平面设计和视频编辑
家庭影院及音响
工业技术
AYX爱游戏app体育官方下载
手机的缺点
保罗·古德曼
2021年1月3日
爱游戏体育代理
娱乐
150个镜子自拍语录和标题创意
通过厚颜无耻的小孩
2021年1月16日
社交网络
195个搞笑又鼓舞人心的Facebook状态更新
由RiciaAnn
2021年1月28日,
文化
很酷的女孩用户名
在卡莉阴沉
2021年1月15日
爱游戏网页版
看在所有科技产品的份上!
为我们写
特约作者:Susan W
软件及操作系统
尝试10个很酷的不和服务器的想法:终极指南
由苏珊W
2021年5月7日,
社交网络
50+可爱的美学用户名和想法:最终列表
由苏珊W
2021年8月19日
社交网络
如何玩不和谐的蛇游戏:终极指南
由苏珊W
2021年9月7日
互联网
社交网络
如何匿名浏览Instagram故事
由肯特Peligrino
2021年10月13日
社交网络
尝试10个很酷的不和谐斜杠命令:最终列表
由苏珊W
2021年10月11日
社交网络
50+ Cottagecore用户名查看:终极列表
由苏珊W
2021年10月8日
电脑
软件及操作系统
如何上传本地文件到AWS S3和DynamoDB
由LT莱特
2021年10月28日
软件及操作系统
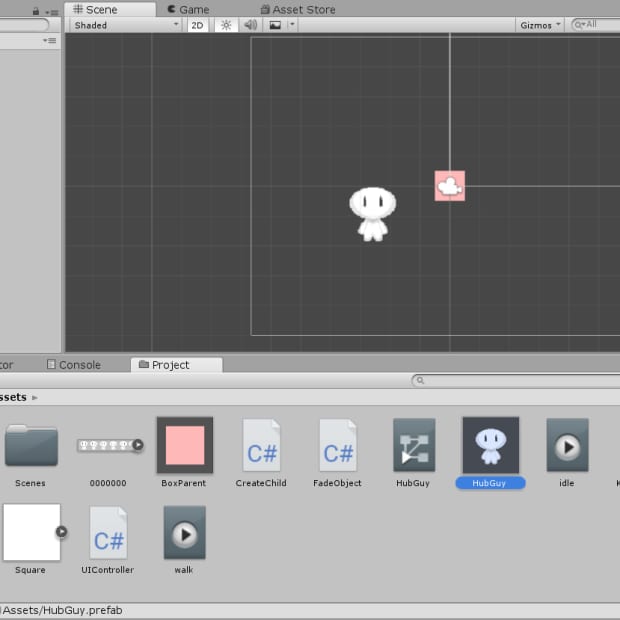
如何在Unity中使用预制件
由马特·鸟
2021年10月29日,
软件及操作系统
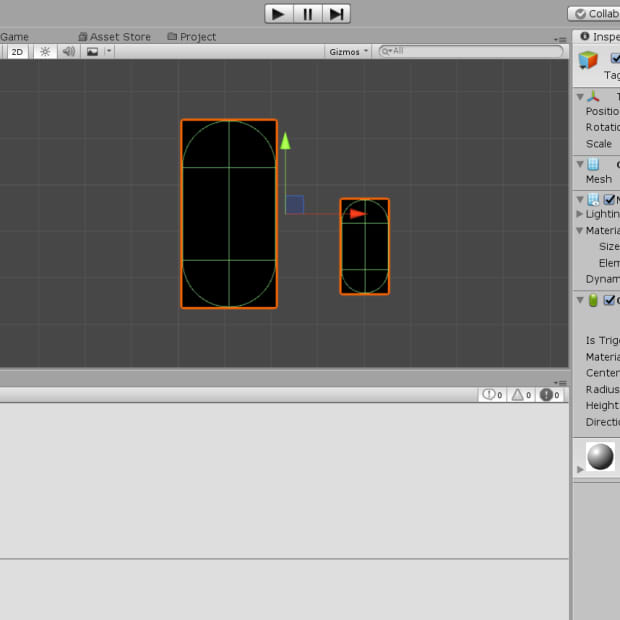
如何在Unity中创建一个子游戏对象
由马特·鸟
2021年10月29日,
手机
AYX爱游戏app体育官方下载
如何使用你的iPhone进行微距摄影
乔纳森·威利
2021年10月13日
爱游戏
2021年十大最佳免费和付费生产力工具
由肯特Peligrino
2021年10月16日
AYX爱游戏app体育官方下载
如何在iPhone上隐藏和查找隐藏的照片
乔纳森·威利
2021年8月16日
消费电子产品
ios爱游戏
10个小贴士让你充分利用你的苹果手表
乔纳森·威利
2021年10月4日,
ios爱游戏
Blackview AirBuds 5 Pro Review:实惠的无线耳机
由西奥
2021年10月6日
ios爱游戏
最好的耳机:Surface耳机2+评论
由Kandice Fyffe
2021年10月6日
平面设计和视频编辑
平面设计和视频编辑
如何从照片制作数字艺术而不绘图
由迈克尔·H
2021年9月24日
平面设计和视频编辑
如何制作带有风格转换的ai生成美术
由迈克尔·H
2021年9月4日
平面设计和视频编辑
图像到ASCII艺术:如何制作文本绘图
由迈克尔·H
2021年8月2日,
家庭影院及音响
家庭影院及音响
Onn 720p高清投影仪的回顾
沃尔特·Shillington
2021年9月22日
演讲者
回顾Jbl Bar 2.1深低音酒吧无线低音炮
沃尔特·Shillington
2021年7月30日
演讲者
评论博梅克奥丁Soundbar
沃尔特·Shillington
2021年6月17日
工业技术
工业技术
机器学习打字手套的ML模型和Arduino编程
由布鲁克(merrill Lynch)
2021年7月11日
工业技术
如何制作更好的机器学习打字手套
由布鲁克(merrill Lynch)
2021年9月19日
工业技术
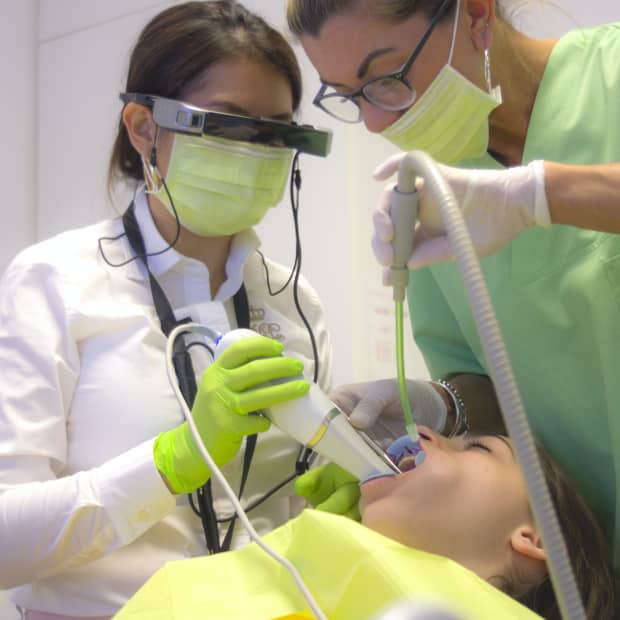
虚拟现实和增强现实:沉浸式医疗的未来
由丽贝卡
2021年6月17日
关闭
关闭
关闭
关闭